简述
最近开始又大数据统计分析,需要将亿级业务数据进行聚合查询统计,传统的关系型库(mysql)已经满足不了业务需求,经过精细的技术选型成本计算后,自建了一个单机(4c16g)的clickhouse。
效果
实现了一个占用内存不到400M,完美将亿级数据从mysql导到了clickhouse(流处理)
问题
建好DB后,接下来的数据导入是个难题。
开始准备使用阿里的datax导入,然后发现clickhouse write模块已经两年没更新了。
 为了快速启动只能先试试用win服务器上的navicat直接导出成csv,然后用命令行导入数据。
两天后…我获得了一个10多个G的CSV,将他上传到clickhouse服务器,敲了下面指令
为了快速启动只能先试试用win服务器上的navicat直接导出成csv,然后用命令行导入数据。
两天后…我获得了一个10多个G的CSV,将他上传到clickhouse服务器,敲了下面指令
clickhouse-client --port=19101 --password ****** --input_format_allow_errors_ratio=0.0001 --date_time_input_format=best_effort --query="insert into db.table format CSVWithNames"< CSV.csv
经过几分钟漫长等待后,导入成功~ 正当欣喜之时,对比了一下两边数据,发现clickhouse少了几W数据 一下就难受了起来。 此时我知道最佳方式就只能来炒一个datax的模式来进行数据的导入了。
又不是不能用
在接触数据导入这块之前,用法从来就是老spring项目里的getJdbcTemplate().query() 然后进行一些数据处理,或是输出,或是写入到其他表(库) 再加上现在用mybatis用的多 所以第一时间就写了个分片select(mysql)Map再 insert (clickhouse) 所谓分片也就是 count出来后再进行limit 0,500000 然后就成功的触发数据库慢查询告警+JVM outofmemory~ 再然后就limit 0,10000,这次没告警但是显然不是很好的解决方案。
解决方案
在翻阅大量文献资料google后,发现jdbc里有一个从来没用过的方法
jdbcTemplate.query()
query(PreparedStatementCreator psc, RowCallbackHandler rch)
它可以通过自定义statement,来流处理查询。
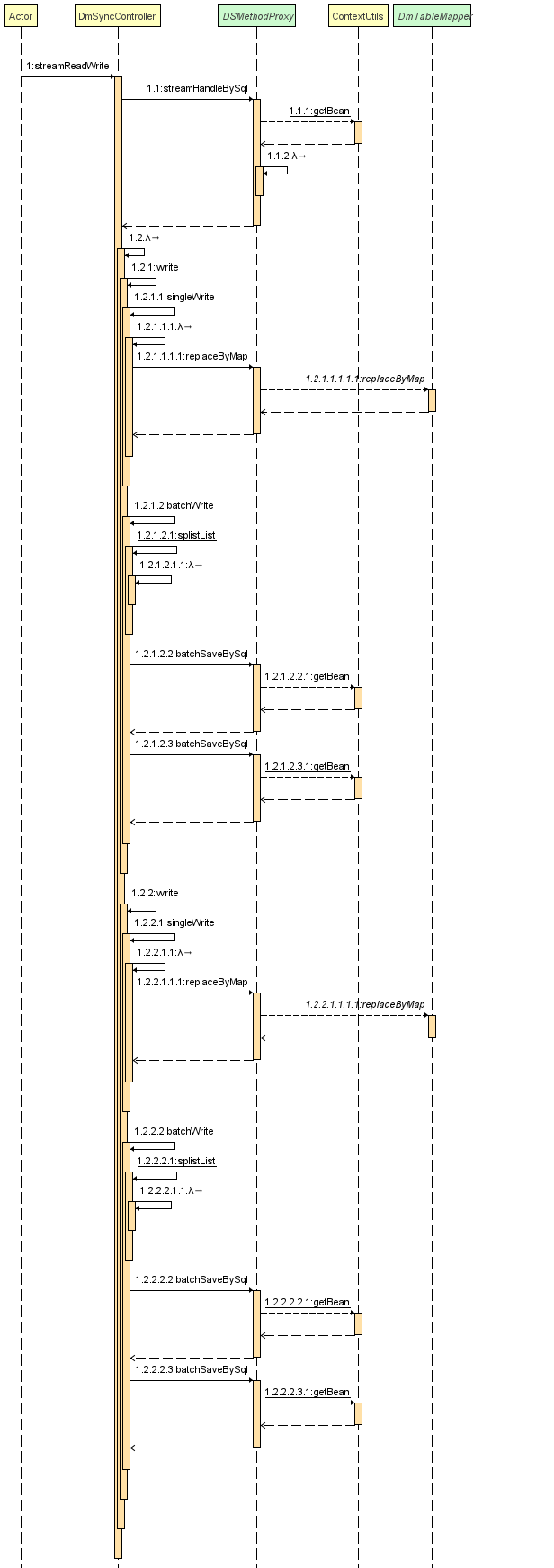
然后就是长达数小时的代码改造(下面是流处理时序图)
代码
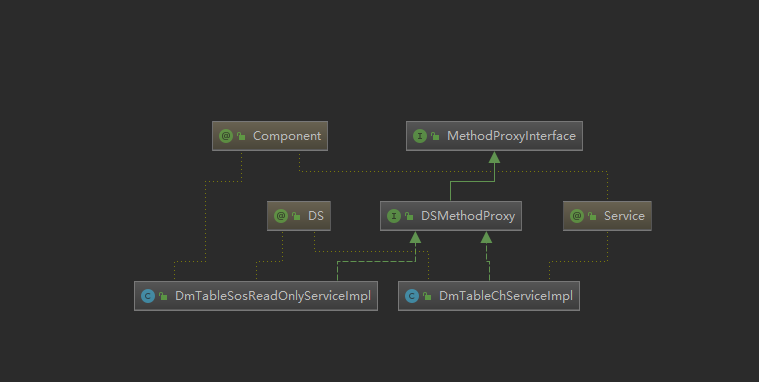
因为涉及到跨实体库,所以首先得需要个proxy来兼容不同库的io操作
于是有了DSMethodProxy这个interface,下面分别对应两个数据源的实现
 在这里面写了流处理实现streamHandleBySql(String sql, RowCallbackHandler rch)
入参是查询的sql和流处理的RowCallbackHandler匿名函数,具体代码如下
在这里面写了流处理实现streamHandleBySql(String sql, RowCallbackHandler rch)
入参是查询的sql和流处理的RowCallbackHandler匿名函数,具体代码如下
default void streamHandleBySql(String sql, RowCallbackHandler rch) {
//获取对应实现的数据源进行查询
DataSource ds = ContextUtils.getBean(DataSource.class);
JdbcTemplate jdbcTemplate = new JdbcTemplate(ds);
//流io
jdbcTemplate.query(psc -> {
PreparedStatement preparedStatement =
psc.prepareStatement(sql,
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
preparedStatement.setFetchSize(Integer.MIN_VALUE);
preparedStatement.setFetchDirection(ResultSet.FETCH_FORWARD);
return preparedStatement;
}, rch);
}
不难发现,这里已经将查询的部分写完了通过自定义statement的sql和fetchSize的设置,查询部分已经写完 接下来则是调用这个streamHandleBySql写入到clickhouse
private void streamReadWrite(Sync sync, String sql) {
//通过来源数据源调用查询数据
sync.getFromProxy().streamHandleBySql(sql, rs -> {
ResultSetMetaData md = rs.getMetaData();
int columnCount = md.getColumnCount();
//批处理列表
List<Map> list = new ArrayList<>();
//逐行转换数据为MAP进行数据写入
while (rs.next()) {
Map<String, Object> rowData = new HashMap<>();
//MetaData -> Map
for (int i = 1; i <= columnCount; i++) {
rowData.put(md.getColumnLabel(i).toLowerCase(), rs.getObject(i));
}
list.add(rowData);
//批处理 当数据量达到NORMAL_INSERT_CHUNK_SIZE时进行写入操作并清空列表gc
if (list.size() >= NORMAL_INSERT_CHUNK_SIZE) {
write(sync, list);
list = new ArrayList<>();
System.gc();
}
}
//最后一批写入
write(sync, list);
});
}
其中Sync对象里可以直接通过sync获取到来源和目标的数据源代理
DSMethodProxy fromProxy;
DSMethodProxy toProxy;
因为clickhouse写入和修改性能较差,所以需要一批一批的写入
当然这里也得考虑部署机器性能问题,单次缓存不宜太大
根据设置环境变量或者定量int NORMAL_INSERT_CHUNK_SIZE来确定每一批的大小
write里的代码就不放了
里面就是将list给写入到目标表里然后做一个断点记录,方便断点续传(各种意外导致的io中断outofmemory)
(绝对不是敏感数据懒得去除)
注意事项
有了上面这些代码,已经可以进行跨库数据导入,甚至可以进行一些简单的数据清洗 经过一些实践操作后总结一下注意事项
- 会产生长连接(一边读一边写,写的时候查询还没断)
- 需要数据库支持长连接(根据每批数据处理大小保持时间不定)
- 使用云库前记得关闭长SQL查询告警或者屏蔽部分sql(不然会一直告警)
- 小内存机器单批处理不建议超过1W(我自己单次执行2W)
- 配合limit分片多线程IO可以不用流处理…很快(源表不会产生数据变动的情况下,否则等于白干)
- 源表不会产生数据变动的情况下可以用limit分片+流处理…更快
以上仅供参考